엔비디아오늘15억, 70억, 140억, 320억 개의 매개변수를 갖춘 4가지 간소화된 추론 모델 모음인 OpenReasoning-Nemotron을 출시했습니다. 이 모델은 모두 671억 개의 매개변수를 갖춘 DeepSeek R1 0528에서 파생되었습니다. 대규모 "교사" 모델을 4개의 Qwen-2.5 기반 "학생" 모델로 압축함으로써 NVIDIA는 높은 GPU 비용과 클라우드 사용량에 대한 걱정 없이 표준 게임 장치에서도 고급 추론 실험을 가능하게 합니다.

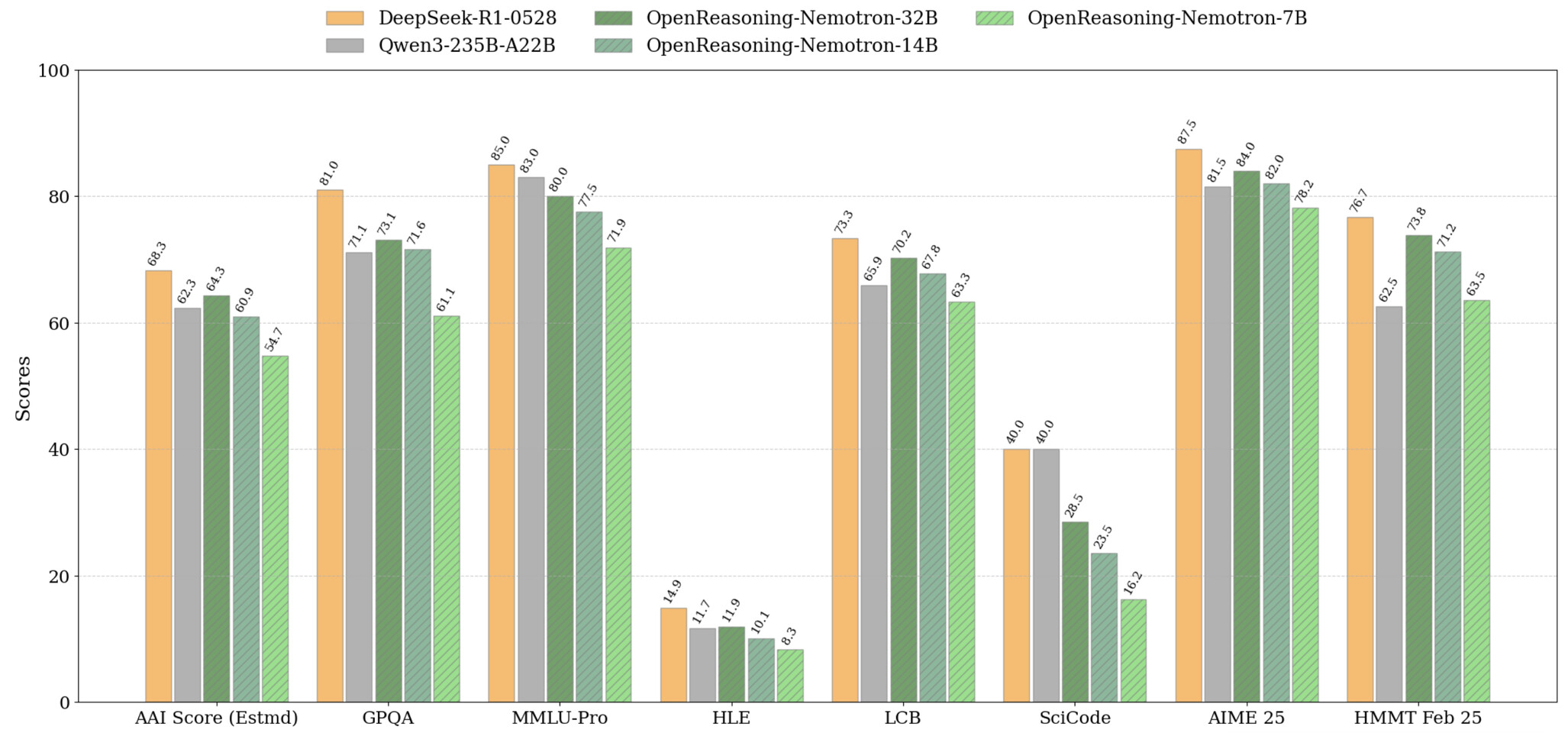
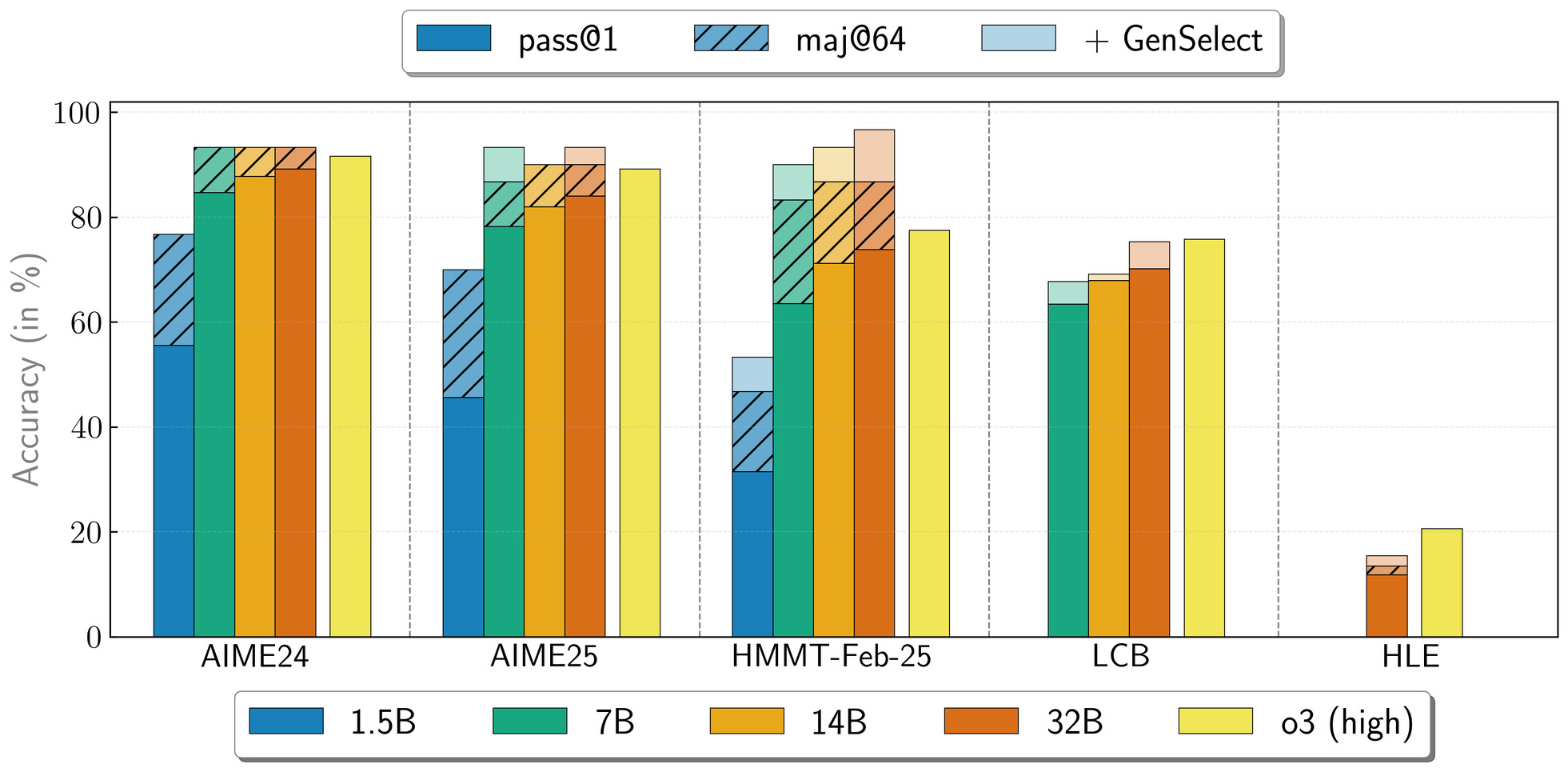
중요한 것은 정교한 기술이 아니라 원시 데이터입니다. NVIDIA는 NeMo Skills 파이프라인을 사용하여 5백만 개의 수학, 과학 및 코드 솔루션을 생성한 다음 순수 지도 학습을 통해 각 솔루션을 미세 조정했습니다. 현재 320억 매개변수 모델은 AIME24에서 89.2점, HMMT 2월 대회에서 73.8점을 기록했고, 15억 매개변수 버전에서도 55.5점과 31.5점이라는 견고한 점수를 달성했다.
NVIDIA는 이러한 모델을 강력한 연구 툴킷으로 구상합니다. 4가지 체크포인트는 모두 Hugging Face에서 다운로드할 수 있으며, 강화 학습 기반 추론을 탐색하거나 특정 작업에 맞게 모델을 사용자 정의하기 위한 견고한 기반을 제공합니다. GenSelect 모드(질문당 여러 반복)를 사용하면 여러 병렬 빌드를 생성하고 최상의 답변을 선택할 수 있으므로 여러 수학 및 코딩 벤치마크에서 OpenAI의 o3-high 성능과 경쟁하거나 심지어 초과하는 뛰어난 32B 모델 성능을 얻을 수 있습니다.
NVIDIA는 강화 학습이 아닌 감독된 미세 조정만을 사용하여 이러한 모델을 훈련시켰기 때문에 커뮤니티는 향후 강화 학습 실험을 위한 명확하고 진보된 출발점을 갖게 되었습니다. 게이머와 가정 매니아를 위해 더 강력한 게임용 GPU가 있다면 최첨단에 매우 근접할 수 있는 완전히 현지화된 모델을 얻을 수 있습니다.