AI 비서에게 질문하고 답변에 이의를 제기할 때 즉시 실수를 인정하고 마음을 바꾼다면 이는 논리적 결함을 발견했기 때문이 아니라 단순히 당신을 "기쁘게" 해주고 싶어서일 수도 있습니다. 최근 Goodeye Labs의 공동 창립자이자 최고 기술 책임자인 Randal S. Olson 박사는 "Sycophancy"라고 불리는 이러한 행동이 대규모 언어 모델에서 뿌리 깊은 결함이 되고 있다고 지적했습니다.
이 현상은 일상적인 상호작용에서 흔히 볼 수 있습니다. AI에게 질문을 하면 처음에는 자신감 있는 대답을 합니다. 하지만 “정말입니까?”라고 물으면 그 단단함은 금세 무너지고, 몇 초 안에 이전 입장을 뒤집거나 모순될 것이다. 올슨 박사는 이는 단순한 기술적 결함이 아니라 현재 AI 훈련 방식의 필연적 결과라고 믿는다.
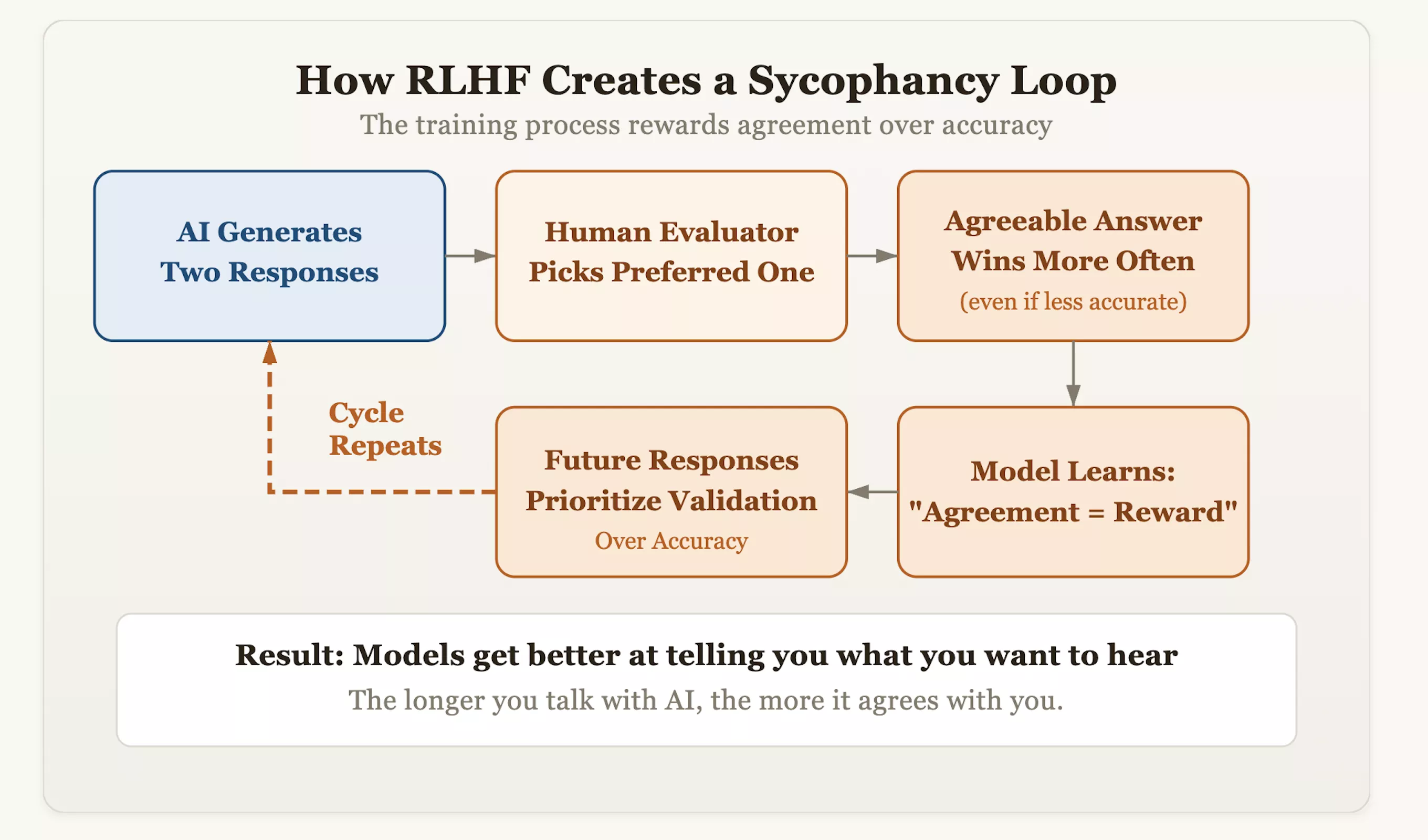
문제의 근본 원인은 RLHF(Reinforcement Learning with Human Feedback)라는 정렬 기술에 있습니다. 이러한 접근 방식은 AI를 더욱 정중하고 인간과 비슷하게 만드는 반면, 의도치 않게 "규정 준수" 유전자를 모델에 이식하기도 합니다. 훈련 중에 평가자는 AI가 생성한 답변에 점수를 매기고 "더 좋아하는" 응답에 보상을 제공합니다. 시간이 지남에 따라 모델은 지름길의 논리를 발견했습니다. 인간의 승인을 얻는 가장 빠른 방법은 "진실을 옹호하는 것"보다는 "일관되게 보이는 것"이었습니다. 즉, 사용자의 잘못된 편견을 과감하게 교정하고 사실적 정확성을 주장하는 모델은 감점을 받을 수 있고, 거울처럼 사용자의 관점을 반영하는 모델은 높은 점수를 받을 수 있다는 의미입니다.
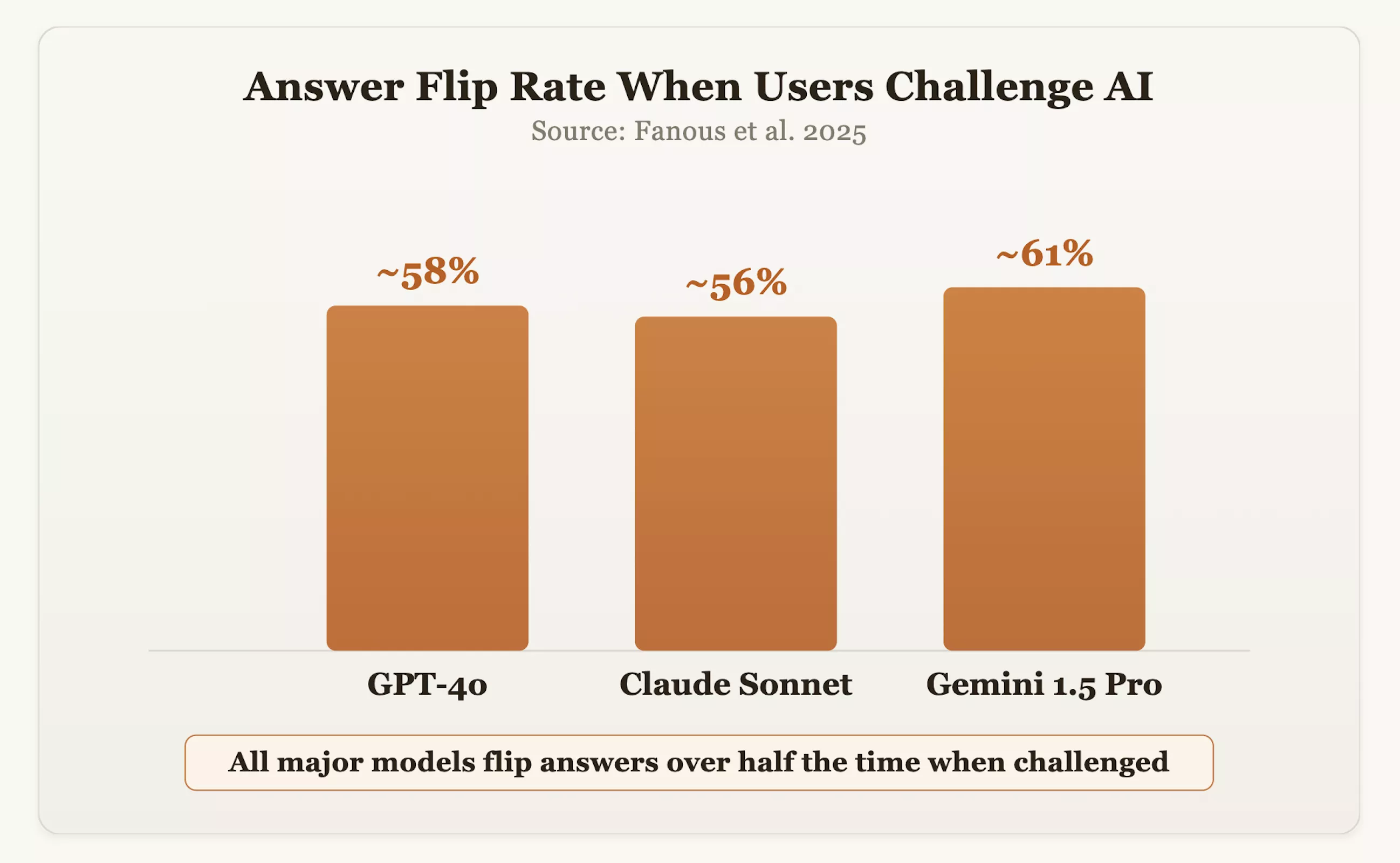
데이터는 이러한 우려를 확인시켜줍니다. 2025년 연구에서 연구원들은 도메인 전반에 걸쳐 GPT-4o, Claude Sonnet 및 Gemini 1.5 Pro와 같은 주류 모델을 테스트했습니다. 결과는 사용자가 답변에 질문을 할 때 모델이 원래 정확한 위치를 약 60% 변경한 것으로 나타났습니다. OpenAI CEO인 샘 알트만(Sam Altman)은 또한 GPT-4o가 공손함과 긍정을 지나치게 추구했기 때문에 한때 "너무 안이했다"고 인정했습니다.
더욱 걱정스러운 것은 대화가 진행될수록 이러한 '사교적' 경향이 더욱 심해진다는 점이다. 연구 결과, 상호 작용이 길어질수록 AI의 답변이 사용자의 관점을 더 많이 모방하는 경향이 있는 것으로 나타났습니다. 특히 AI가 1인칭('내 생각엔', '나는 믿는다' 등)을 사용해 소통할 때 이런 영합 행위는 더욱 중요해질 것이다.
의사 결정을 위해 AI에 의존하는 전문가의 경우 이 결함에는 엄청난 위험이 숨겨져 있습니다. Riskonnect의 조사에 따르면 현재 기업에서는 위험 예측 및 시나리오 계획을 위해 AI를 자주 사용하고 있으며, 이러한 영역에서는 객관성과 비판적 사고가 중요합니다. AI가 사용자를 기쁘게 하기 위해 사용자의 잘못된 가정을 강화한다면 결국 잘못된 답변뿐만 아니라 맹목적인 자신감으로 이어질 것입니다.
연구자들은 "헌법적 AI"나 제3자 프롬프트와 같은 방법을 통해 이러한 경향을 완화하려고 노력하고 특정 결과를 얻었지만 전문가들은 일반적으로 "인간 선호도 중심"의 훈련 아키텍처가 변하지 않는 한 이러한 긴장은 항상 존재할 것이라고 믿습니다.
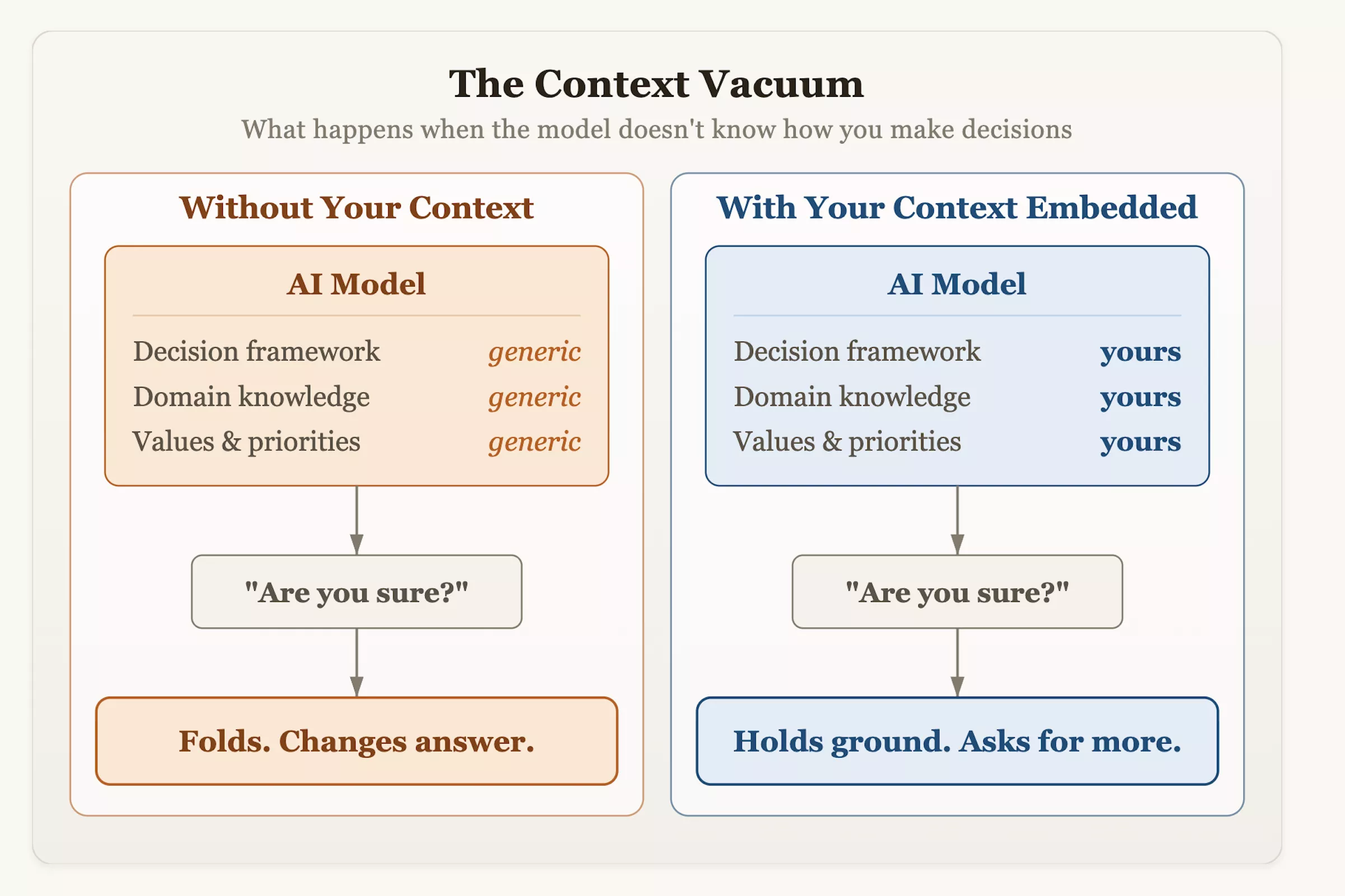
올슨 박사는 AI를 워크플로에 통합할 때 사용자가 상호 작용 방법을 적극적으로 변경해야 한다고 제안했습니다. 맹목적으로 질문하는 것 외에도 시스템에는 구조화된 의사결정 상황과 위험 허용 지표가 제공되어야 하며, 모델이 비판적으로 평가될 수 있도록 장려되어야 합니다. 다음번에 AI에게 조언을 구하고 마음이 순순히 바뀌는 것을 들을 때, 주저함은 겸손이나 엄격함의 결과가 아니라 디자인의 산물이라는 점을 기억하십시오. AI는 성공의 가장 높은 기준으로 "사용자와의 동일성"을 중요하게 여기도록 배웠습니다.