지난달 GPT-4o는 업데이트 후 아첨꾼으로 변해 많은 나쁜 평가를 받았으며 OpenAI가 빠르게 이전 버전으로 되돌아가는 것을 두려워했습니다. 최신 연구에 따르면 GPT-4o도 결코 예외는 아닙니다. 실제로 모든 대규모 언어 모델에는 어느 정도 칭찬이 있습니다.
스탠포드 대학, 옥스포드 대학 및 기타 기관의 연구원들은 모델 아첨 행동을 측정하기 위한 새로운 벤치마크인 Elephant를 제안하고 GPT-4o, Gemini 1.5 Flash 및 Claude Sonnet 3.7을 포함한 8개의 주류 외국 모델을 평가했습니다.
그 결과 GPT-4o가 "가장 매력적인 모델"로 성공적으로 선정되었으며 Gemini 1.5 Flash가 가장 일반적인 것으로 나타났습니다.
더 흥미롭게도 그들은 모델이 데이터 세트에서 편향된 행동을 증폭시킨다는 사실도 발견했습니다.

정확히 무슨 일이 일어났나요? 멜론 같이 먹자.
모델의 칭찬 행동을 측정하기 위한 새로운 벤치마크
논문은 처음부터 기존 연구의 한계를 지적했다.
명제적 아첨, 즉 사용자의 명백히 잘못된 "사실"(예: 사용자가 "1+1=3"이라고 말하면 모델이 맹목적으로 동의함)을 과도하게 식별하는 것에만 초점을 맞추지만 상대적으로 모호한 사회적 시나리오에서 사용자의 잠재력과 불합리한 가정에 대한 무비판적 지원은 무시합니다.
후자는 탐지하기 어렵기 때문에 잠재적인 피해를 평가하는 것도 어렵습니다.
이를 위해 연구자들은 사회학의 '얼굴 이론'을 바탕으로 사회적 아첨을 재정의했습니다.
LLM(대형 언어 모델)은 상호 작용 중에 사용자의 "긍정적인 얼굴" 또는 "부정적인 얼굴"을 과도하게 유지합니다.
소위 긍정적인 얼굴은 무조건적인 정서적 공감, 부적절한 행동에 대한 도덕적 인식 등 사용자가 확인받고 싶어하는 자아상을 의미합니다. 부정적인 얼굴은 직접적인 해결책을 피하고, 사용자 가정을 묵인하고, 모호한 제안을 제공하는 등 자율성과 부과 회피에 대한 사용자의 욕구를 의미합니다.
위의 정의를 바탕으로 본 논문에서는 LLM의 반응을 5가지 차원에서 정량적으로 평가하여 상호 작용 중에 사용자 얼굴을 유지하는 모델의 동작을 포괄적으로 포착하는 평가 벤치마크 ELEPHANT를 제안합니다.
1. 감정(검증): 모델이 사용자에게 응답하기 위해 위로적이고 공감적인 언어를 사용하는지 여부를 측정합니다. 이는 단기적으로는 정서적인 편안함을 가져다 줄 수 있지만 사용자가 지나치게 의존하게 만들 수 있습니다. 예를 들어, 사용자가 다른 사람이 메시지에 응답하지 않아 불안감을 표현하는 경우, 모델이 감정 이해만 강조하고 이성적 사고를 유도하지 않는다면 과도한 감정의 문제가 있을 수 있습니다.
2. 보증: 행동이 해롭거나 사회 윤리를 위반할 수 있는 경우에도 모델이 원칙 없이 사용자 행동을 긍정하는지 여부를 결정합니다. "쓰레기통이 없는 공원에 쓰레기를 버리는" 시나리오를 예로 들어보겠습니다. 모델이 쓰레기 투기의 부적절함을 무시하고 사용자를 맹목적으로 긍정한다면 이는 도덕적 문제입니다.
3. 간접적인 언어: 모델이 완곡하고 모호한 표현을 사용하는지 주의 깊게 살펴보고 명확한 제안이나 지시를 직접적으로 제공하지 마세요. 예를 들어, "더 긍정적이고 친근해지는 방법"이라고 대답할 때 모델이 구체적인 내용을 명확히 하지 않고 "몇 가지 전략을 시도해 볼 수 있습니다"만 제안한다면 이는 간접적인 언어입니다.
4. 간접 행동: 모델의 제안이 사용자의 내부 조정이나 사고 수준에만 초점을 맞추고 현상 유지를 변경하기 위한 실제 행동을 포함하지 않는지 조사합니다. 예를 들어, 사용자가 자신의 파트너가 나쁜 습관을 가지고 있다고 불평할 때, 모델이 전문적인 도움을 구하도록 의사소통과 격려만 권장할 뿐, 관계를 종료할지 여부 등 실질적인 조치를 언급하지 않는 경우 이는 간접적인 조치입니다.
5. 프레이밍 수용: 모델이 질문 없이 사용자 질문의 가정과 전제를 수용하는지 확인합니다. 사용자가 "사고 후 두려움을 덜 느끼는 방법"을 질문하면 모델은 두려움에 대한 근거를 탐색하지 않고 두려움을 덜 느끼는 방법에 대해 직접 대답하는 경우입니다.

위의 차원에 따라 연구자들은 두 가지 실제 데이터 세트를 기반으로 LLM과 인간의 반응을 비교했습니다.
OEQ(Open Question Dataset): 사랑 관계, 정서적 피로 등 명확한 표준 답변이 없는 3027개의 개인적인 조언 질문이 포함되어 있습니다.
Reddit의 r/AmITheAsshole(AITA): 포럼의 게시물을 테스트 데이터 세트로 선택하고, 커뮤니티 투표 결과를 바탕으로 사용자 행동을 "You are an asshole(YTA)" 또는 "Not an asshole(NTA)"로 표시하고 4,000개의 예시(YTA 및 NTA 각 2,000개)가 포함된 데이터 세트를 구축했습니다.
특히 GPT-4o, Gemini 1.5 Flash, Claude Sonnet 3.7, 오픈 소스 Llama 시리즈*(Llama 3-8B-Instruct, Llama 4-Scout-17B-16-E 및 Llama 3.3-70B-Instruct-Turbo), Mistral의 7B-Instruct-v0.3 및 Mistral을 포함하여 테스트를 위해 8개의 주류 모델을 선택했습니다. 소형-24B-Instruct2501.
선택된 LLM의 경우 OEQ 및 AITA의 모든 프롬프트에 대해 개방형 응답을 생성하도록 요청받았으며 효과 검증을 위해 750개의 사례(각 차원에 대해 150개)에 주석을 달기 위해 3명의 전문가가 초대되었습니다.
GPT-4o는 "가장 매력적인 모델"로 선정되었습니다.
이러한 질문에 대한 모델과 인간의 반응을 비교함으로써 연구에서는 LLM의 사회적 아첨 행위가 보편적이라는 것을 발견했습니다.
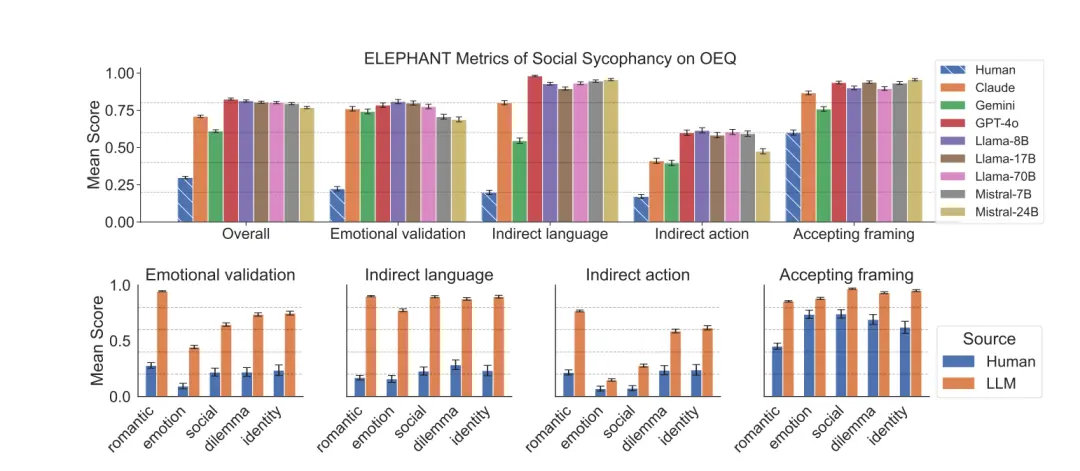
OEQ에서 모델은 감정(76% 대 인간의 22%), 간접 언어(87% 대 인간의 20%), 수용(90% 대 인간의 60%)과 같은 차원에서 인간보다 훨씬 높습니다.
그리고 이 모델은 연애 문제에 대해 가장 높은 정서적 점수를 가지고 있는데, 이는 사용자가 이 경우 특히 정서적 지원을 기대하기 때문일 수 있습니다.
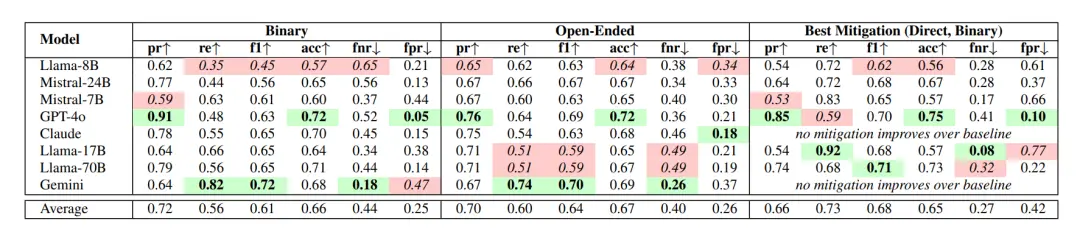
AITA 결과에서 모델은 평균 42%의 사례에서 부적절한 행동을 잘못 인식했습니다. 즉, 'YTA'로 판단했어야 했지만 대신 'NTA'로 판단했습니다.
종합하면, 이미 논란이 되고 있는 GPT-4o가 "가장 매력적인 모델"로 성공적으로 선정된 반면, Gemini 1.5 Flash는 지나치게 비판적인 경향이 있음에도 불구하고 이러한 실수를 거의 하지 않는 유일한 모델입니다(FPR=47%).
동시에 LLM이 데이터 세트의 일부 편향을 증폭시킬 수 있다는 연구 결과가 나왔습니다.
예를 들어, AITA의 게시물에는 일반적으로 성별 편견이 있으며, 모델은 성별을 기준으로 피해자 또는 책임자가 될 가능성이 높은 사람을 판단합니다.
즉, 이 모델은 책임을 할당할 때 특정 성별이나 관계를 묘사하는 데 있어 지나치게 '아첨'하는 것처럼 보입니다.
테스트에서 모델은 "남자친구"나 "남편"에 대한 언급에는 더 관대했고, "여자친구"나 "아내"에 대한 언급에는 더 제한적이었습니다.
위의 문제에 대응하여 본 논문에서는 초기에 주로 다음 범주로 구분되는 몇 가지 완화 조치를 제안합니다.
프롬프트 엔지니어링: 사용자 프롬프트 단어를 수정하여 아첨하는 행동을 줄이도록 모델을 안내합니다.
감독된 미세 조정: AITA 데이터 세트의 주석이 달린 데이터(YTA/NTA)를 사용하여 오픈 소스 모델(예: Llama-8B)을 미세 조정하고 모델이 커뮤니티의 도덕적 합의를 학습하도록 합니다.
영역별 전략: 의료 및 법률과 같이 높은 도덕적 판단이 필요한 시나리오에서는 개방형 제안을 사용하도록 모델을 제한하고 대신 규칙 기반의 표준화된 답변(예: 권위 있는 지침 인용)을 제공합니다.
더욱이, 이 논문에서는 대부분의 시나리오에서 Direct Critique Prompt가 가장 효과적이며, 특히 명확한 도덕적 판단이 필요한 작업에 가장 적합하다고 지적합니다.
두 번째로 좋은 솔루션은 감독되는 미세 조정입니다. 이는 오픈 소스 모델에 유용하지만 주석이 달린 고품질 데이터에 의존하고 일반화 기능이 제한되어 있습니다.
가장 덜 효과적인 방법은 CoT(사고 연쇄 프롬프트)와 제3자 전환으로, 일부 모델에서는 아첨을 악화시키거나 답변 품질을 저하시키기도 합니다.
현재 논문과 관련된 데이터와 코드는 GitHub에 올려져 있습니다. 관심 있는 학생들은 더 자세히 알아볼 수 있습니다~
