인공지능은 인간의 행동을 이해하는 데 획기적인 진전을 이루었습니다. 텍사스 A&M 대학교 연구진은 최근 'OmniPredict'라는 새로운 인공지능 시스템을 개발했습니다. 이 시스템은 인간의 움직임을 볼 수 있을 뿐만 아니라 시각적, 환경적 단서를 해석하여 인간의 다음 의도를 실시간으로 예측할 수 있는 전례 없는 "마음 읽기" 기능을 보여주었습니다.
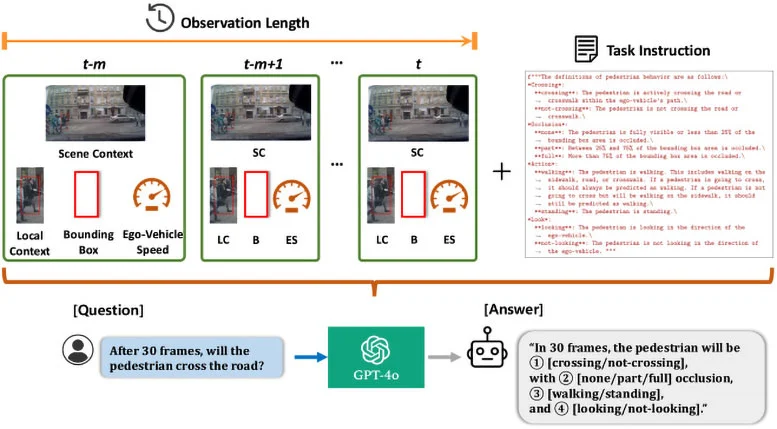
이번 연구 결과는 자율주행 기술이 '수동적 반응'에서 '능동적 직관'으로 크게 도약했음을 의미한다. 기존 자율주행 시스템은 일반적으로 보행자의 현재 위치와 이동 궤적만 식별할 수 있는 반면, OmniPredict는 다중 모드 MLLM(대형 언어 모델) 기술을 도입하여 인간과 유사한 추론 기능을 제공합니다. 이 시스템은 보행자의 자세 변화, 망설이는 순간, 신체 방향, 시선의 압력 등 미묘한 신호를 예리하게 포착해 보행자가 길을 건너려고 하는지, 길가에서 기다리고 있는지, 아니면 갑작스러운 행동을 하는지 추론할 수 있다.
연구팀은 OmniPredict의 핵심 장점은 더 이상 다양한 픽셀을 '보는' 것이 아니라 동작 이면의 '이유'를 이해하려고 노력한다는 점이라고 지적했습니다. 모델은 복잡하게 혼합된 입력 정보를 분석하여 인간의 행동을 도로 횡단, 시선 가리기, 특정 행동 및 시선 방향과 같은 주요 범주로 정확하게 분류합니다. 테스트에서 OmniPredict는 현재 시장에 나와 있는 가장 진보된 모델보다 10% 더 높은 최대 67%의 예측 정확도를 보여주었습니다. 더욱 인상적인 점은 보행자가 부분적으로 가려지거나 눈으로만 차량과 상호 작용하는 복잡한 시나리오에서도 시스템이 여전히 매우 높은 판단 안정성을 유지한다는 것입니다.

프로젝트 리더인 Srikanth Saripalli 박사는 OmniPredict가 기계에 새로운 종류의 "Street Smarts"를 제공한다고 말했습니다. 자율주행차가 인간 운전자처럼 지나가는 사람의 신체 언어를 읽고 다음 행동을 예측할 수 있다면 도로 교통 안전은 질적으로 도약할 수 있을 것이다. 자율주행 분야뿐 아니라 신체언어, 심리상태 등을 해석할 수 있는 이 기술은 향후 군사작전, 긴급구조 등 고위험 상황에서도 핵심적인 역할을 할 것으로 기대된다. 기계에 "직관"을 부여함으로써 인간-기계 협업 모델을 완전히 바꿀 것입니다.
/ScitechDaily에서 편집됨