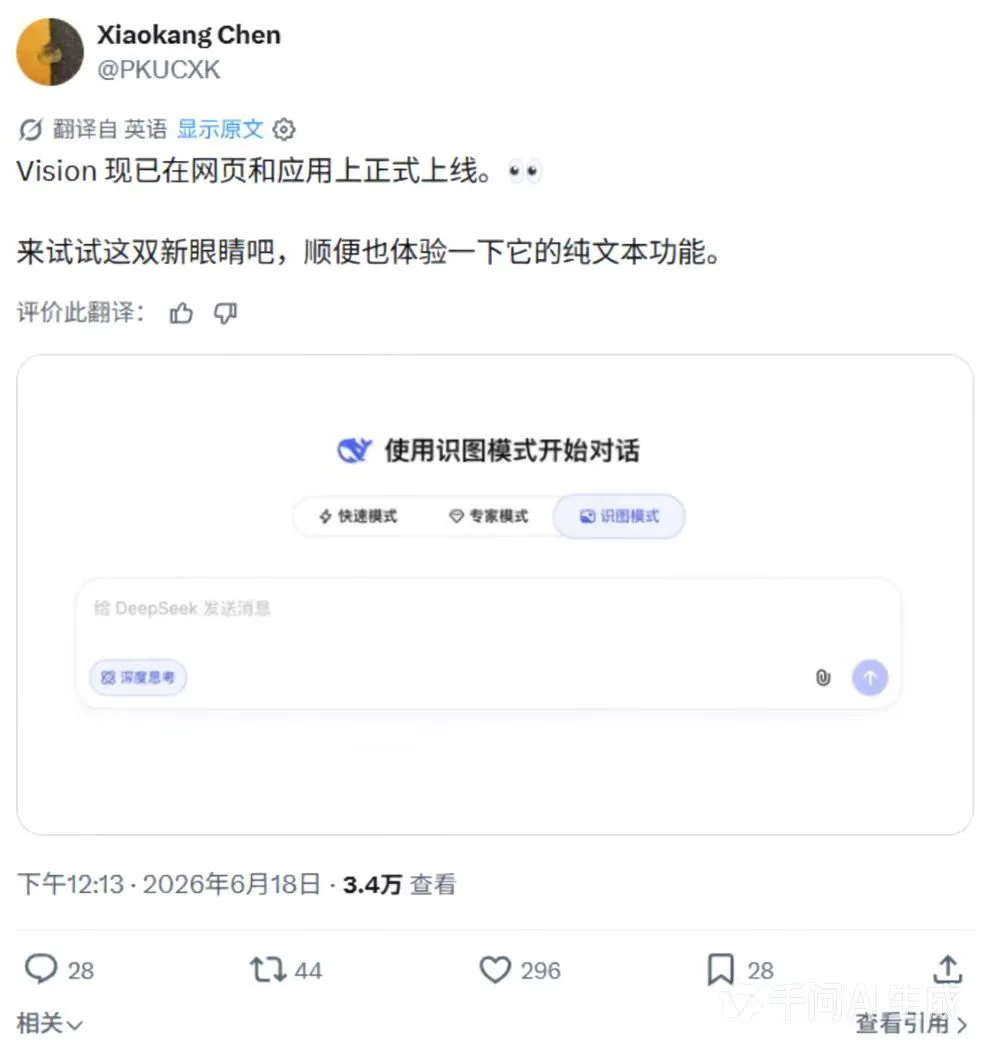
6월 18일, DeepSeek 다중 모드 연구원 Chen Xiaokang은 DeepSeek의 이미지 인식 모드가 공식적으로 웹과 앱에 출시되었다고 게시했습니다. 쿼리 결과 DeepSeek 앱 측의 이미지 인식 모드에서 여전히 "이미지 이해 기능은 내부 테스트 중입니다"라는 메시지가 표시되지만 웹 페이지에는 그러한 메시지가 없는 것으로 나타났습니다.
그러나 미디어 테스트에 따르면 DeepSeek은 사람을 식별하는 데 정확도가 떨어지는 것으로 나타났습니다. 예를 들어 상사인 Liang Wenfeng을 알아보지 못했습니다. 한 순간에는 그를 왕싱(Wang Xing)으로 인식했고, 다른 순간에는 그를 다른 사람으로 인식했습니다.


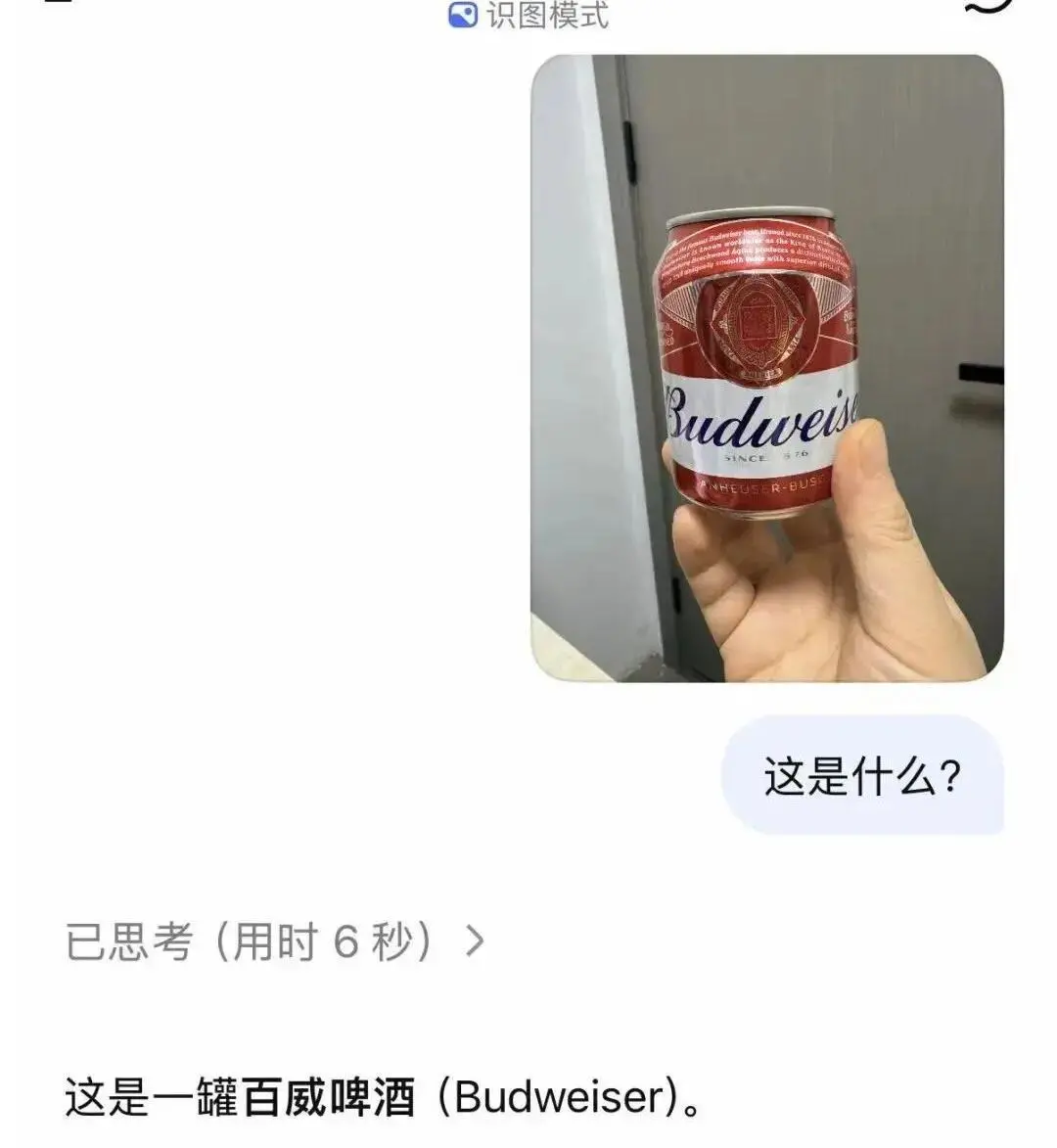
그러나 일반적인 물체와 잘 알려진 건물을 식별하는 것은 상대적으로 정확했습니다.
보도에 따르면 두 달 전 DeepSeek 이미지 인식 모드가 그레이스케일로 공식 출시되었습니다. 기본 시각적 상호 작용 포털인 DeepSeek 이미지 인식 모드는 고속 모드 및 전문가 모드와 함께 독립적인 1단계 기능입니다. 초기 순수 텍스트 모델의 기능 제한을 완전히 제거하고 이미지와 텍스트가 포함된 통합된 대화 경험을 달성합니다.
DeepSeek 이미지 인식 모드는 단순한 이미지 텍스트 추출 도구나 단순한 OCR 도구가 아니라 자체 개발한 DeepSeek-OCR2 시각적 인과 흐름 메커니즘을 사용하여 완전한 시각적 이해 폐쇄 루프를 구축한다는 점을 기억해야 합니다. 사용자는 텍스트 질문이 포함된 사진을 직접 업로드하기만 하면 되며 시스템은 객체 인식, 장면 분석, 차트 분해, 정밀한 텍스트 추출 및 세부 마이닝을 동시에 완료할 수 있습니다.
DeepSeek은 최근 시리즈 A 자금 조달을 완료했으며, 자금 조달 금액은 약 510억 위안, 투자 후 기업 가치는 약 4000억 위안에 달하는 것으로 알려졌습니다.